<<< Chap 10 | Sommaire | Chap 12 >>>
Chap 11. Création d’un Volume Persistant via un serveur NFS
I. Serveur NFS et de stockage de données Kubernetes
1. Stockage de données
Chaque conteneur peut utiliser l’une des méthodes ci-dessous, pour écrire et sauvegarder des données dans un espace disque qui lui est aloué.
Pour reprendre le résumé donné dans le chap 10 de cette série d’articles sur kubernetes, la persistance des données d’un conteneur dépend du type de système de stockage choisi:
- Filesystem
Un redémarrage du conteneur réinitialise l’état du disque
Exemples: voir chap 4 et 10
— - Volume
Les données sont préservées jusqu’au redémarrage ou à la destruction du Pod concerné
Exemple de Volumes: emptyDir (voir chap 10 et 8), et hostPath
— - Persistent Volume
Les données sont préservées sur un système de stockage externe (NAS, SAN), indépendement de l’état du conteneur ou du Pod/Node
Exemple: serveur NFS associé au couple PV/PVC (persistentVolume/persistentVolumeClaim)
Dans cet article,
- Je vais utiliser le node Master comme serveur NFS
Si vous avez du mal à configurer votre serveur NFS, déployez un conteneur NFS - Je vais vous présenter deux types de volumes qui sont, hostPath et PV/PVC
2. Configuration du node Master comme serveur NFS (Option 1)
Je vous propose de suivre les instructions de cet article, pour configurer le cluster kubernetes comme suit:
- Installer le serveur NFS sur le Master (Control Plane)
- Adresse IP du serveur: 192.168.0.200
- NFS export: /srv/nfs/k8sn01
- Installer les clients NFS sur chacun des Workers
- Adresse IP des client NFS: 192.168.0.201 et 192.168.0.202
- Mount: /mnt/pvs/k8sn01 (ne monter le(s) disque(s) dans les clients NFS que dans le cas d’un Volume de type hostPath uniquement)
Placer ensuite un fichier de test dans /srv/nfs/k8sn01 pour vérifier que chacun des clients NFS y ont accès.

L’utilisation du Master comme serveur NFS ne devrait ête en aucun cas, appliquée en production. Pensez plutôt à deployer un vrai serveur de type, FreeNAS TrueNAS ou NAS4Free XigmaNAS.
Pour un environnement de lab, cette configuration est largement suffisante pour apprendre à utiliser les fonctionnalités de kubernetes.
3. Déployement d’un Serveur NFS via un conteneur (Option 2)
Commencer par appliquer le fichier nfs-server.yaml dans kubernetes.
k8sn01:~$ kubectl create -f https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/deploy/example/nfs-provisioner/nfs-server.yamlSi vous examiner le contenu du fichier nfs-server.yaml, vous devriez constater qu’il est composé d’un Service (voir chap 9 pour plus d’information sur les services) puis d’un contrôleur de Déploiement.
Le service de nfs-servernous permettra d’accéder de l’extérieur du clusteur, au serveur NFS créé par le contrôleur de Déploiement.
Je dois préciser que le chemin d’accès aux fichiers NFS est donné par /. C’est cette information qu’il faudra renseigner au niveau de « share: / » dans les fichiers YAMLs des Volumes de type Persitant (statique ou dynamique), pour pouvoir accéder aux fichiers du serveur NFS.
- Pour un Volume Persistant Statique (obsolète)
apiVersion: v1
kind: PersistentVolume
...
csi:
driver: nfs.csi.k8s.io
...
volumeAttributes:
server: nfs-server.default.svc.cluster.local
share: /- Pour un Volume Persistant Dynamique (recommandée)
apiVersion: storage.k8s.io/v1
kind: StorageClass
...
provisioner: nfs.csi.k8s.io
parameters:
server: nfs-server.default.svc.cluster.local
share: /
...Ensuite, installer le pilote CSI (Interface de stockage de conteneurs) pour système NFS. Ce pilote peut être utilisé pour provisionner les Volymes Persistants de type Statique ou Dynamique.
L’interface de stockage de conteneurs (CSI) définit une interface standard pour les systèmes d’orchestration de conteneurs (comme Kubernetes) pour exposer des systèmes de stockage arbitraires aux charges de travail de leurs conteneurs. (Documentation Kubernetes)
k8sn01:~$ curl -skSL https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/deploy/install-driver.sh | bash -s master --La liste des pilotes installés peut être affichée avec la commande,
k8sn01:~$ kubectl get pod -n kube-system
Quand vous en aurez fini avec le lab, supprimer le conteneur NFS.
k8sn01:~$ kubectl delete -f https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/deploy/example/nfs-provisioner/nfs-server.yamlSi vous n’en avez plus besoin, vous pouvez aussi désinstaller le pilote NFS CSI.
k8sn01:~$ curl -skSL https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/deploy/uninstall-driver.sh | bash -s master --II. hostPath lié à un système de fichier NFS
Un volume de type hostPath permet de monter le système de fichier NFS partagé par un serveur NFS directement dans le pod concerné, pour le présenter comme un de ces disques locaux.
k8sn01:~$ cat << EOF >> hostpath.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: nfs-busybox
name: nfs-busybox
spec:
replicas: 2
selector:
matchLabels:
run: nfs-busybox
template:
metadata:
labels:
run: nfs-busybox
spec:
containers:
- image: busybox
name: nfs-busybox
command:
- sh
- -c
- 'while true; do date > /mnt/index.html; hostname >> /mnt/index.html; \
sleep $(($RANDOM % 5 + 5)); done'
imagePullPolicy: Always
volumeMounts:
- name: nfs-volume
mountPath: /mnt
volumes:
- name: nfs-volume
hostPath:
path: /mnt/pvs/k8sn01/
EOF
k8sn01:~$ kubectl create -f hostpath.yamlVérifier que vous avez accès aux contenus du répertoire partagé par le serveur NFS.
k8sn01:~$ kubectl get pod
k8sn01:~$ kubectl exec -it nfs-hostpath -- cat /mnt/test.txt
k8sn01:~$ kubectl exec -it nfs-hostpath -- touch /mnt/hostpath-test.txt
Les changements apportés devraient être visible aussi bien du coté du client que du serveur NFS.
 Les données modifiés devraients persister même après suppression des Pods.
Les données modifiés devraients persister même après suppression des Pods.
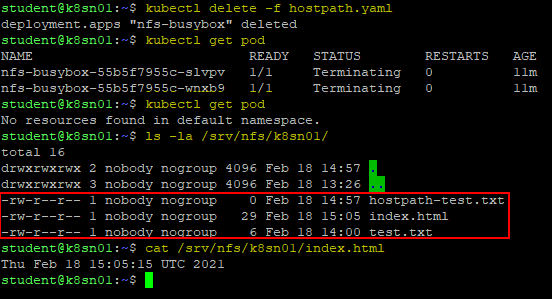
Noter que l’option de Volume du type hostPath est la seule méthode où les Workers doivent monter le système de fichier proposé par le serveur NFS.
Une fois l’exercice terminé, vous pouvez démonter ce système de fichier.
k8sn02:~$ sudo umount /mnt/pvs
k8sn03:~$ sudo umount /mnt/pvs III. Approvisionnement statique avec PersistentVolumeClaim
Pour rappel, monter manuellement un système de fichiers NFS au niveau des differents workers n’est pas nécessaire, kubernetes s’en occupera du processus.
Ce qu’il nous faut pour un approvisionnement de type statique des Volumes, vous devriez avoir:
- Un ou plusieurs PVs (Volumes Persistants)
- Un PVC (Réclamation du ou des volumes persistants)
- Un ou plusieurs Pods pour « réclamer » l’espace de stockage à l’aide d’un PVC
k8sn01:~$ cat << EOF >> nfs-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv-slow01
spec:
capacity:
storage: 10Mi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.2
nfs:
server: 192.168.0.200
path: /k8sn01
EOF
k8sn01:~$ kubectl apply -f nfs-pv.yamlAttention: La politique de récupération
Recycleest obsolète. Au lieu de cela, l’approche recommandée consiste à utiliser l’approvisionnement dynamique. (Documentation Kubernetes)
k8sn01:~$ cat << EOF >> nfs-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc-01
spec:
accessModes:
- ReadWriteMany
storageClassName: "slow"
resources:
requests:
storage: 1Mi
EOF
k8sn01:~$ kubectl apply -f nfs-pvc.yamlNoter qu’un PV avec une classe définie (ici, storageClassName: slow) ne peut être lié qu’avec un PVC demandant la même classe (ici, storageClassName: "slow").
Si aucune classe n’est définie au niveau des PVs (par exemple, storageClassName: , ou si l’option n’a pas été ajoutée dans le fichier yaml), les volumes présentées par les PVs ne peuvent être réclamés que par les PVC « sans classe », qui ne demandent aucun classe particulière (par exemple, storageClassName: "").
k8sn01:~$ cat << EOF >> nfs-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: nfs-busybox
name: nfs-busybox
spec:
replicas: 2
selector:
matchLabels:
run: nfs-busybox
template:
metadata:
labels:
run: nfs-busybox
spec:
containers:
- image: busybox
name: nfs-busybox
command:
- sh
- -c
- 'while true; do date > /mnt/index.html; hostname >> /mnt/index.html; \
sleep $(($RANDOM % 5 + 5)); done'
imagePullPolicy: Always
volumeMounts:
- name: nfs-volume
mountPath: "/mnt"
volumes:
- name: nfs-volume
persistentVolumeClaim:
claimName: nfs-pvc-01
EOF
k8sn01:~$ kubectl apply -f nfs-deploy.yaml 
A la destruction du cluster dans l’ordre inverse de sa création, le serveur NFS est vidé de son contenu.

Ceci est le résultat de l’option Recycleappliqué au PV/PVC.
La stratégie de récupération
Recycleeffectue un nettoyage de base (rm -rf /thevolume/*) sur le volume et le rend à nouveau disponible pour une nouvelle demande. (Documentation Kubernetes)
Pour cette raison, il n’est pas souhaitable d’utiliser un Volume Persistant de type Statique.
IV. Volume Persistant Dynamique
Avant de pouvoir utiliser un système de Volume de type Persistant et Dynamique, installer les pilotes CSI (Interface de stockage de conteneurs) pour système NFS, si vous ne l’avez pas encore fait.
k8sn01:~$ curl -skSL https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/deploy/install-driver.sh | bash -s master --Ce qu’il nous faut pour un approvisionnement de type dynamique des Volumes,
- Un
StorageClasspour définir la « classe » du stockage - Un PVC (Réclamation du ou des volumes persistants)
- Un ou plusieurs Pods pour « réclamer » l’espace de stockage à l’aide d’un PVC
- Le PV est créé automatiquement
k8sn01:~$ cat << EOF >> nfs-class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi
provisioner: nfs.csi.k8s.io
parameters:
server: 192.168.0.200
share: /k8sn01
reclaimPolicy: Retain
volumeBindingMode: Immediate
mountOptions:
- hard
- nfsvers=4.2
EOF
k8sn01:~$ cat << EOF >> nfs-pv-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-nfs-dynamic
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Mi
storageClassName: nfs-csi
EOFk8sn01:~$ cat << EOF >> nfs-dyn-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: nfs-busybox
name: nfs-busybox
spec:
replicas: 2
selector:
matchLabels:
run: nfs-busybox
template:
metadata:
labels:
run: nfs-busybox
spec:
containers:
- image: busybox
name: nfs-busybox
command:
- sh
- -c
- 'while true; do date > /mnt/index.html; hostname >> /mnt/index.html; \
sleep $(($RANDOM % 5 + 5)); done'
imagePullPolicy: Always
volumeMounts:
# name must match the volume name below
- name: dyn-volume
mountPath: "/mnt"
volumes:
- name: dyn-volume
persistentVolumeClaim:
claimName: pvc-nfs-dynamic
Contrairement au cas d’un Cluster dont le Volume est approvisionné statiquement, la destruction du cluster dynamique n’a pas d’impact sur le contenu du serveur NFS. Rien n’y est supprimé.

V. Suppression de Pods resté dans un état de blocage
Durant ce chapitre, il se peut qu’à la suppression des différents Pods, l’un d’entre eux reste dans un état de « hang » (bloqué).
Pour forcer la suppression du Pod récalcitrant,
k8sn01:~$ kubectl delete pod nginx-nfs-example --grace-period=0 --force
Sources
Kubernetes Storage 101
Kubernetes – Volumes
Kubernetes Volumes Guide
Kubernetes persistent volume on own rack
Kubernetes : Dynamic Persistent Volume provisioning using NFS
CSI NFS driver
Install NFS CSI driver master version on a kubernetes cluster
Dynamic Provisioning and Creating Storage Classes
Force Delete StatefulSet Pods